
Ph.D. (Computer Science and Engineering)
Principal Researcher/Research Manager
Spatial Intelligence Group
Microsoft Research Asia (MSRA)
Microsoft Homepage
Jiaolong (蛟龙): the given name from my parents. "Jiaolong" is an aquatic dragon in Chinese ancient legends with great power. It can be pronounced as "chiao-lung".
Yang (杨): the family name from my forefathers, the sixth most common surname in China. It can be pronounced as the word "young" with a rising tone.

| Bio |
|
I'm currently a Principal Researcher and Research Manager in the Microsoft Research Asia (MSRA) Lab located in Beijing, China. I lead a team to do cutting-edge research in 3D Computer Vision and Spatial AI, including but not limited to 3D reconstruction and generation, human face & body modelling, immersive AI experiences, and physical AI embodiments. Part of my research has been transfered to various Microsoft Products such as Microsoft Copilot, Microsoft Azure AI, Microsoft Cognitive Services, Windows Hello, Microsoft XiaoIce, etc. I serve regularly as the program committee member/reviewer for major computer vision conferences and journals including CVPR/ICCV/ECCV/TPAMI/IJCV, the Area Chair for CVPR/ICCV/ECCV/WACV/MM, and the Associate Editor for the prestigious journal International Journal on Computer Vision (IJCV).
Before joining MSRA in Sep 2016, I received dual PhD degrees from The Australian National University (Advisor: Prof. Hongdong Li) and Beijing Institute of Technology (Advisor: Prof. Yunde Jia) in 2016. I was a research intern at MSRA from Nov 2015 to Mar 2016 (Mentor: Dr. Gang Hua), and was an visiting graduate researcher at Harvard University between Jul 2016 and Aug 2016 (Host: Dr. Deqing Sun). I received the Excellent PhD Thesis Award from China Society of Image and Graphics (中国图形图像学会优博) in 2017 (4 recipients in China), the Best Paper Award of IEEE VR 2022, and the Best Paper Honorable Mention Award of IEEE VR 2025. |
| Publications (Google Scholar) |
|
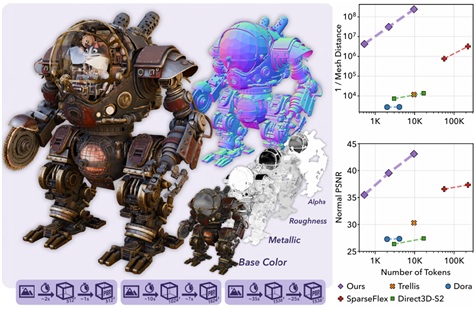
Jianfeng Xiang+, Xiaoxue Chen+, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, Jiaolong Yang$ Native and Compact Structured Latents for 3D Generation arXiv preprint, 2025 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA $: Corresponding author) |
|
Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
@article{xiang2025native,
author = {Xiang, Jianfeng and Chen, Xiaoxue and Xu, Sicheng and Wang, Ruicheng and Lv, Zelong and Deng, Yu and Zhu, Hongyuan and Dong, Yue and Zhao, Hao and Yuan, Nicholas Jing and Yang, Jiaolong}, title = {Native and Compact Structured Latents for 3D Generation}, journal = {arXiv preprint arXiv:2512.14692}, year = {2025} } |
|

|
Qixiu Li*, Yu Deng*, Yaobo Liang*, Lin Luo*, Lei Zhou, Chengtang Yao, Lingqi Zeng, Zhiyuan Feng, Huizhi Liang, Sicheng Xu, Yizhong Zhang, Xi Chen, Hao Chen, Lily Sun, Dong Chen, Jiaolong Yang$, Baining Guo Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos arXiv preprint, 2025 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributions $: Corresponding author) |
|
This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
@article{li2025scalable,
author = {Li, Qixiu and Deng, Yu and Liang, Yaobo and Luo, Lin and Zhou, Lei and Yao, Chengtang and Zeng, Lingqi and Feng, Zhiyuan and Liang, Huizhi and Xu, Sicheng and Zhang, Yizhong and Chen, Xi and Chen, Hao and Sun, Lily and Chen, Dong and Yang, Jiaolong and Guo, Baining}, title = {Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos}, journal = {arXiv preprint arXiv:2510.21571}, year = {2025} } |
|

|
Z. Feng*, Z. Kang*, Q. Wang*, Z. Du*, J. Yan, S. Shi, C. Yuan, H. Liang, Y. Deng, Q. Li, R. Yang, R. An, L. Zheng, W. Wang, S. Chen, S. Xu, Y. Liang, J. Yang$, B. Guo Seeing Across Views: Benchmarking Spatial Reasoning of Vision-Language Models in Robotic Scenes arXiv preprint, 2025 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributions $: Corresponding author) |
|
Vision-language models (VLMs) are essential to Embodied AI, enabling robots to perceive, reason, and act in complex environments. They also serve as the foundation for the recent Vision-Language-Action (VLA) models. Yet, most evaluations of VLMs focus on single-view settings, leaving their ability to integrate multi-view information largely underexplored. At the same time, multi-camera setups are increasingly standard in robotic platforms, as they provide complementary perspectives to mitigate occlusion and depth ambiguity. Whether VLMs can effectively leverage such multi-view inputs for robotic reasoning therefore remains an open question. To bridge this gap, we introduce MV-RoboBench, a benchmark specifically designed to evaluate the multi-view spatial reasoning capabilities of VLMs in robotic manipulation. MV-RoboBench consists of 1.7k manually curated QA items across eight subtasks, divided into two primary categories: spatial understanding and robotic execution. We evaluate a diverse set of existing VLMs, including both open-source and closed-source models, along with enhanced versions augmented by CoT-inspired enhancements. The results show that state-of-the-art models remain far below human performance, underscoring the substantial challenges VLMs face in multi-view robotic perception. Additionally, our analysis uncovers two key findings: (i) spatial intelligence and robotic task execution are correlated in multi-view robotic scenarios; and (ii) strong performance on existing general-purpose single-view spatial understanding benchmarks does not reliably translate to success in the robotic spatial tasks assessed by our benchmark. We release MV-RoboBench as an open resource to foster progress in spatially grounded VLMs and VLAs, providing a foundation for advancing embodied multi-view intelligence in robotics.
@article{feng2025seeing,
author = {Feng, Zhiyuan and Kang, Zhaolu and Wang, Qijie and Du, Zhiying and Yan, Jiongrui and Shi, Shubin and Yuan, Chengbo and Liang, Huizhi and Deng, Yu and Li, Qixiu and Xu, Sicheng and Liang, Yaobo and Yang, Jiaolong and Guo, Baining}, title = {Seeing Across Views: Benchmarking Spatial Reasoning of Vision-Language Models in Robotic Scenes}, journal = {arXiv preprint arXiv:2510.19400}, year = {2025} } |
|
|
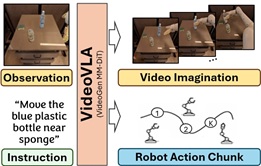
Yichao Shen+, Fangyun Wei$, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang$, Nanning Zheng$, Baining Guo VideoVLA: Video Generators Can Be Generalizable Robot Manipulators The 39th Annual Conference on Neural Information Processing Systems (NeurIPS2025) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA $: Corresponding author) |
|
Generalization in robot manipulation is essential for deploying robots in open-world environments and advancing toward artificial general intelligence. While recent Vision-Language-Action (VLA) models leverage large pre-trained understanding models for perception and instruction following, their ability to generalize to novel tasks, objects, and settings remains limited. In this work, we present VideoVLA, a simple approach that explores the potential of transforming large video generation models into robotic VLA manipulators. Given a language instruction and an image, VideoVLA predicts an action sequence as well as the future visual outcomes. Built on a multi-modal Diffusion Transformer, VideoVLA jointly models video, language, and action modalities, using pre-trained video generative models for joint visual and action forecasting. Our experiments show that high-quality imagined futures correlate with reliable action predictions and task success, highlighting the importance of visual imagination in manipulation. VideoVLA demonstrates strong generalization, including imitating other embodiments' skills and handling novel objects. This dual-prediction strategy—forecasting both actions and their visual consequences—explores a paradigm shift in robot learning and unlocks generalization capabilities in manipulation systems.
@inproceedings{wang2025moge2,
author = {Shen, Yichao and Wei, Fangyun and Du, Zhiying and Liang, Yaobo and Lu, Yan and Yang, Jiaolong and Zheng, Nanning and Guo, Baining}, title = {VideoVLA: Video Generators Can Be Generalizable Robot Manipulators}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2025} } |
|
|
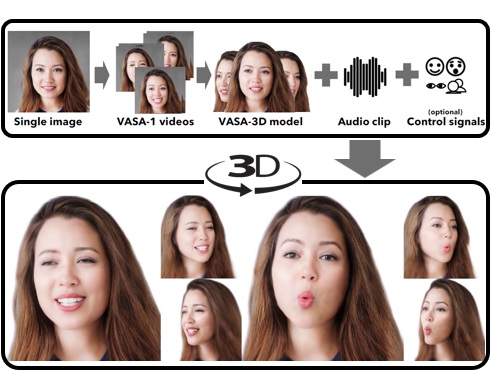
Sicheng Xu*, Guojun Chen*, Jiaolong Yang$, Yizhong Zhang, Stephen Lin, Baining Guo VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image The 39th Annual Conference on Neural Information Processing Systems (NeurIPS2025) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributions $: Corresponding author) |
|
We propose VASA-3D, an audio-driven, single-shot 3D head avatar generator. This research tackles two major challenges: capturing the subtle expression details present in real human faces, and reconstructing an intricate 3D head avatar from a single portrait image. To accurately model expression details, VASA-3D leverages the motion latent of VASA-1, a method that yields exceptional realism and vividness in 2D talking heads. A critical element of our work is translating this motion latent to 3D, which is accomplished by devising a 3D head model that is conditioned on the motion latent. Customization of this model to a single image is achieved through an optimization framework that employs numerous video frames of the reference head synthesized from the input image. The optimization takes various training losses robust to artifacts and limited pose coverage in the generated training data. Our experiment shows that VASA-3D produces realistic 3D talking heads that cannot be achieved by prior art, and it supports the online generation of 512x512 free-viewpoint videos at up to 75 FPS, facilitating more immersive engagements with lifelike 3D avatars.
@inproceedings{xu2025vasa3d,
author = {Xu, Sicheng and Chen, Guojun and Yang, Jiaolong and Zhang, Yizhong and Deng, Yu and Lin, Stephen and Guo, Baining}, title = {VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2025} } |
|

|
Ruicheng Wang+, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang+, Zelong Lv+, Guangzhong Sun, Xin Tong, Jiaolong Yang$ MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details The 39th Annual Conference on Neural Information Processing Systems (NeurIPS2025) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA $: Corresponding author) |
|
We propose MoGe-2, an advanced open-domain geometry estimation model that recovers a metric scale 3D point map of a scene from a single image. Our method builds upon the recent monocular geometry estimation approach, MoGe, which predicts affine-invariant point maps with unknown scales. We explore effective strategies to extend MoGe for metric geometry prediction without compromising the relative geometry accuracy provided by the affine-invariant point representation. Additionally, we discover that noise and errors in real data diminish fine-grained detail in the predicted geometry. We address this by developing a unified data refinement approach that filters and completes real data from different sources using sharp synthetic labels, significantly enhancing the granularity of the reconstructed geometry while maintaining the overall accuracy. We train our model on a large corpus of mixed datasets and conducted comprehensive evaluations, demonstrating its superior performance in achieving accurate relative geometry, precise metric scale, and fine-grained detail recovery -- capabilities that no previous methods have simultaneously achieved.
@inproceedings{wang2025moge2,
author = {Wang, Ruicheng and Xu, Sicheng and Dong, Yue and Deng, Yu and Xiang, Jianfeng and Lv, Zelong and Sun, Guangzhong and Tong, Xin and Yang, Jiaolong}, title = {MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2025} } |
|

|
Bowen Zhang, Sicheng Xu, Chuxin Wang, Jiaolong Yang, Feng Zhao, Dong Chen, Baining Guo Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis The 20th International Conference on Computer Vision (ICCV2025) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
In this paper, we present a novel framework for video-to-4D generation that creates high-quality dynamic 3D content from single video inputs. Direct 4D diffusion modeling is extremely challenging due to costly data construction and the high-dimensional nature of jointly representing 3D shape, appearance, and motion. We address these challenges by introducing a Direct 4DMesh-to-GS Variation Field VAE that directly encodes canonical Gaussian Splats (GS) and their temporal variations from 3D animation data without per-instance fitting, and compresses high-dimensional animations into a compact latent space. Building upon this efficient representation, we train a Gaussian Variation Field diffusion model with temporal-aware Diffusion Transformer conditioned on input videos and canonical GS. Trained on carefully-curated animatable 3D objects from the Objaverse dataset, our model demonstrates superior generation quality compared to existing methods. It also exhibits remarkable generalization to in-the-wild video inputs despite being trained exclusively on synthetic data, paving the way for generating high-quality animated 3D content.
@inproceedings{zhang2025gaussian,
author = {Zhang, Bowen and Xu, Sicheng and Wang, Chuxin and Yang, Jiaolong and Zhao, Feng and Chen, Dong and Guo, Baining}, title = {Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, year = {2025} } |
|
|
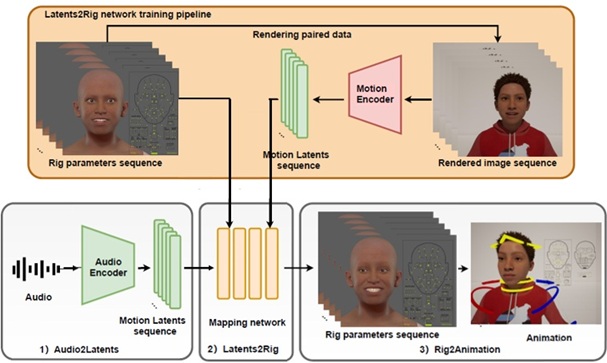
Ye Pan, Chang Liu, Sicheng Xu, Shuai Tan, Jiaolong Yang$ VASA-Rig: Audio-Driven 3D Facial Animation with 'Live' Mood Dynamics in Virtual Reality IEEE Conference on Virtual Reality and 3D User Interfaces (VR2025) (& IEEE TVCG) (Best Paper Honorable Mention Award) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
Audio-driven 3D facial animation is crucial for enhancing the metaverse's realism, immersion, and interactivity. While most existing methods focus on generating highly realistic and lively 2D talking head videos by leveraging extensive 2D video datasets these approaches work in pixel space and are not easily adaptable to 3D environments. We present VASA-Rig, which has achieved a significant advancement in the realism of lip-audio synchronization, facial dynamics, and head movements. In particular, we introduce a novel rig parameter-based emotional talking face dataset and propose the Latents2Rig model, which facilitates the transformation of 2D facial animations into 3D. Unlike mesh-based models, VASA-Rig outputs rig parameters, instantiated in this paper as 174 Metahuman rig parameters, making it more suitable for integration into industry-standard pipelines. Extensive experimental results demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of both realism and accuracy.
@article{ye2025vasarig,
author = {Ye, Pan and Liu, Chang and Xu, Sicheng and Tan, Shuai and Yang, Jiaolong}, title = {VASA-Rig: Audio-Driven 3D Facial Animation with 'Live' Mood Dynamics in Virtual Reality}, journal = {IEEE Transactions on Visualization and Computer Graphics}, year = {2025} } |
|

|
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jisang Han, Jiaolong Yang$, Chong Luo$, Seungryong Kim$ PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting The 42th International Conference on Machine Learning (ICML2025) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] ($: Corresponding author) |
|
We consider the problem of novel view synthesis from unposed images in a single feed-forward. Our framework capitalizes on fast speed, scalability, and high-quality 3D reconstruction and view synthesis capabilities of 3DGS, where we further extend it to offer a practical solution that relaxes common assumptions such as dense image views, accurate camera poses, and substantial image overlaps. We achieve this through identifying and addressing unique challenges arising from the use of pixel-aligned 3DGS: misaligned 3D Gaussians across different views induce noisy or sparse gradients that destabilize training and hinder convergence, especially when above assumptions are not met. To mitigate this, we employ pre-trained monocular depth estimation and visual correspondence models to achieve coarse alignments of 3D Gaussians. We then introduce lightweight, learnable modules to refine depth and pose estimates from the coarse alignments, improving the quality of 3D reconstruction and novel view synthesis. Furthermore, the refined estimates are leveraged to estimate geometry confidence scores, which assess the reliability of 3D Gaussian centers and condition the prediction of Gaussian parameters accordingly. Extensive evaluations on large-scale real-world datasets demonstrate that PF3plat sets a new state-of-the-art across all benchmarks, supported by comprehensive ablation studies validating our design choices.
@inproceedings{hong2024pf3plat,
author = {Hong, Sunghwan and Jung, Jaewoo and Shin, Heeseong and Han, Jisang and Yang, Jiaolong and Luo, Chong and Kim, Seungryong}, title = {PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting}, booktitle = {International Conference on Machine Learning}, year = {2025} } |
|
|
Wenbo Wang, Fangyun Wei, Lei Zhou, Xi Chen, Lin Luo, Xiaohan Yi, Yizhong Zhang, Yaobo Liang, Chang Xu, Yan Lu, Jiaolong Yang, Baining Guo UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping The 41th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2025) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
|
We introduce UniGraspTransformer, a universal Transformer-based network for dexterous robotic grasping that simplifies training while enhancing scalability and performance. Unlike prior methods such as UniDexGrasp++, which require complex, multi-step training pipelines, UniGraspTransformer follows a streamlined process: first, dedicated policy networks are trained for individual objects using reinforcement learning to generate successful grasp trajectories; then, these trajectories are distilled into a single, universal network. Our approach enables UniGraspTransformer to scale effectively, incorporating up to 12 self-attention blocks for handling thousands of objects with diverse poses. Additionally, it generalizes well to both idealized and real-world inputs, evaluated in state-based and vision-based settings. Notably, UniGraspTransformer generates a broader range of grasping poses for objects in various shapes and orientations, resulting in more diverse grasp strategies. Experimental results demonstrate significant improvements over state-of-the-art, UniDexGrasp++, across various object categories, achieving success rate gains of 3.5%, 7.7%, and 10.1% on seen objects, unseen objects within seen categories, and completely unseen objects, respectively, in the vision-based setting.
@inproceedings{wang2025unigrasptransformer,
author = {Wang, Wenbo and Wei, Fangyun and Zhou, Lei and Chen, Chen and Luo, Lin, and Yi, Xiaohan and Zhang, Yizhong and Liang, Yaobo and Xu, Chang and Lu, Yan and Yang, Jiaolong and Guo, Baining}, title = {UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025} } |
|

|
Jianfeng Xiang+, Zelong Lv+, Sicheng Xu, Yu Deng, Ruicheng Wang+, Bowen Zhang, Dong Chen, Xin Tong, Jiaolong Yang$ Structured 3D Latents for Scalable and Versatile 3D Generation The 41th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2025) (Highlight) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA $: Corresponding author) |
|
We introduce a novel 3D generation method for versatile and high-quality 3D asset creation. The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding.
We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.
@inproceedings{xiang2025structured,
author = {Xiang, Jianfeng and Lv, Zelong and Xu, Sicheng and Deng, Yu and Wang, Ruicheng and Zhang, Bowen and Chen, Dong and Tong, Xin and Yang, Jiaolong}, title = {Structured 3D Latents for Scalable and Versatile 3D Generation}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025} } |
|

|
Ruicheng Wang+, Sicheng Xu, Cassie Dai+, Jianfeng Xiang+, Yu Deng, Xin Tong, Jiaolong Yang$ MoGe: Unlocking Accurate Monocular Geometry Estimation for Open-Domain Images with Optimal Training Supervision The 41th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2025) (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA $: Corresponding author) |
|
We present MoGe, a powerful model for recovering 3D geometry from monocular open-domain images. Given a single image, our model directly predicts a 3D point map of the captured scene with an affine-invariant representation, which is agnostic to true global scale and shift. This new representation precludes ambiguous supervision in training and facilitate effective geometry learning. Furthermore, we propose a set of novel global and local geometry supervisions that empower the model to learn high-quality geometry. These include a robust, optimal, and efficient point cloud alignment solver for accurate global shape learning, and a multi-scale local geometry loss promoting precise local geometry supervision. We train our model on a large, mixed dataset and demonstrate its strong generalizability and high accuracy. In our comprehensive evaluation on diverse unseen datasets, our model significantly outperforms state-of-the-art methods across all tasks including monocular estimation of 3D point map, depth map, and camera field of view.
@inproceedings{wang2024moge,
author = {Wang, Ruicheng and Xu, Sicheng and Dai, Cassie and Xiang, Jianfeng and Deng, Yu and Tong, Xin and Yang, Jiaolong}, title = {MoGe: Unlocking Accurate Monocular Geometry Estimation for Open-Domain Images with Optimal Training Supervision}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025} } |
|

|
Qixiu Li*, Yaobo Liang*$, Zeyu Wang*, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang$, Baining Guo CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation arXiv preprint, 2024 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Equal contributions $: Corresponding author) |
|
The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation.
@inproceedings{li2024cogact,
author = {Li, Qixiu and Liang, Yaobo and Wang, Zeyu and Luo, Lin and Chen, Xi and Liao, Mozheng and Wei, Fangyun and Deng, Yu and Xu, Sicheng and Zhang, Yizhong and Wang, Xiaofan and Liu, Bei and Fu, Jianlong and Bao, Jianmin and Chen, Dong and Shi, Yuanchun and Yang, Jiaolong and Guo, Baining}, title = {CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation}, booktitle = {arXiv preprint arXiv:2411.19650}, year = {2024} } |
|
|
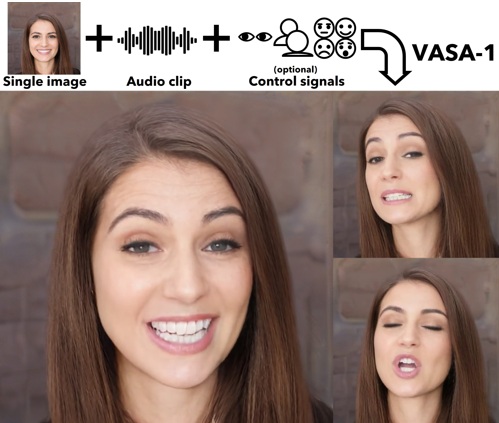
Sicheng Xu*, Guojun Chen*, Yu-Xiao Guo*, Jiaolong Yang*$, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, Baining Guo VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time The 38th Annual Conference on Neural Information Processing Systems (NeurIPS2024) (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributions $: Corresponding author) |
|
We introduce VASA, a framework for generating lifelike talking faces of virtual characters with appealing visual affective skills (VAS), given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
@inproceedings{xu2024vasa,
author = {Xu, Sicheng and Chen, Guojun and Guo, Yu-Xiao and Yang, Jiaolong and Li, Chong and Zang, Zhenyu and Zhang, Yizhong and Tong, Xin and Guo, Baining}, title = {VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2024} } |
|

|
Bowen Zhang+, Yiji Chen+, Jiaolong Yang, Chunyu Wang, Feng Zhao, Yansong Tang, Dong Chen, Baining Guo GaussianCube: A Structured and Explicit Radiance Representation for 3D Generative Modeling The 38th Conference on Neural Information Processing Systems (NeurIPS2024) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
3D Gaussian Splatting (GS) have achieved considerable improvement over Neural Radiance Fields in terms of 3D fitting fidelity and rendering speed. However, this unstructured representation with scattered Gaussians poses a significant challenge for generative modeling. To address the problem, we introduce GaussianCube, a structured GS representation that is both powerful and efficient for generative modeling. We achieve this by first proposing a modified densification-constrained GS fitting algorithm which can yield high-quality fitting results using a fixed number of free Gaussians, and then re-arranging the Gaussians into a predefined voxel grid via Optimal Transport. The structured grid representation allows us to use standard 3D U-Net as our backbone in diffusion generative modeling without elaborate designs. Extensive experiments conducted on ShapeNet and OmniObject3D show that our model achieves state-of-the-art generation results both qualitatively and quantitatively, underscoring the potential of GaussianCube as a powerful and versatile 3D representation.
@inproceedings{zhang2024gaussiancube,
author = {Zhang, Bowen and Chen, Yiji and Wang, Chunyu and Zhao, Feng and Tang, Yansong and Chen, Dong and Guo, Baining}, title = {GaussianCube: Structuring Gaussian Splatting using Optimal Transport for 3D Generative Modeling}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2024} } |
|

|
Ruicheng Wang+, Jianfeng Xiang+, Jiaolong Yang, Xin Tong Diffusion Models are Geometry Critics: Single Image 3D Editing Using Pre-Trained Diffusion Priors The 18th European Conference on Computer Vision (ECCV2024) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
We propose a novel image editing technique that enables 3D manipulations on single images, such as object rotation and translation. Existing 3D-aware image editing approaches typically rely on synthetic multi-view datasets for training specialized models, thus constraining their effectiveness on open-domain images featuring significantly more varied layouts and styles. In contrast, our method directly leverages powerful image diffusion models trained on a broad spectrum of text-image pairs and thus retain their exceptional generalization abilities. This objective is realized through the development of an iterative novel view synthesis and geometry alignment algorithm. The algorithm harnesses diffusion models for dual purposes: they provide appearance prior by predicting novel views of the selected object using estimated depth maps, and they act as a geometry critic by correcting misalignments in 3D shapes across the sampled views. Our method can generate high-quality 3D-aware image edits with large viewpoint transformations and high appearance and shape consistency with the input image, pushing the boundaries of what is possible with single-image 3D-aware editing.
@inproceedings{wang2024diffusion,
author = {Wang, Ruicheng and Xiang, Jianfeng and Yang, Jiaolong and Tong, Xin}, title = {Diffusion Models are Geometry Critics: Single Image 3D Editing Using Pre-Trained Diffusion Priors}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2024} } |
|

|
Bowen Zhang*, Yiji Chen*, Chunyu Wang, Ting Zhang, Jiaolong Yang, Yansong Tang, Dong Chen, Baining Guo RodinHD: High-Fidelity 3D Avatar Generation with Diffusion Models The 18th European Conference on Computer Vision (ECCV2024) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributuons.) |
|
We present RodinHD, which can generate high-fidelity 3D avatars from a portrait image. Existing methods fail to capture intricate details such as hairstyles which we tackle in this paper. We first identify an overlooked problem of catastrophic forgetting that arises when fitting triplanes sequentially on many avatars, caused by the MLP decoder sharing scheme. To overcome this issue, we raise a novel data scheduling strategy and a weight consolidation regularization term, which improves the decoder's capability of rendering sharper details. Additionally, we optimize the guiding effect of the portrait image by computing a finer-grained hierarchical representation that captures rich 2D texture cues, and injecting them to the 3D diffusion model at multiple layers via cross-attention. When trained on 46K avatars with a noise schedule optimized for triplanes, the resulting model can generate 3D avatars with notably better details than previous methods and can generalize to in-the-wild portrait input.
@inproceedings{zhang2024rodinhd,
author = {Zhang, Bowen and Chen, Yiji and Wang, Chunyu and Zhang, Ting and Yang, Jiaolong and Tang, Yansong and Chen, Dong and Guo, Baining}, title = {RodinHD: High-Fidelity 3D Avatar Generation with Diffusion Models}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2024} } |
|
|
Ronglai Zuo, Fangyun Wei, Zenggui Chen, Brian Mak, Jiaolong Yang, Xin Tong A Simple Baseline for Spoken Language to Sign Language Translation with 3D Avatars The 18th European Conference on Computer Vision (ECCV2024) (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
|
Sign languages are visual languages using manual articulations and non-manual elements to convey information. For sign language recognition and translation, the majority of existing approaches directly encode RGB videos into hidden representations. RGB videos, however, are raw signals with substantial visual redundancy, leading the encoder to overlook the key information for sign language understanding. To mitigate this problem and better incorporate domain knowledge, such as handshape and body movement, we introduce a dual visual encoder containing two separate streams to model both the raw videos and the keypoint sequences generated by an off-the-shelf keypoint estimator. To make the two streams interact with each other, we explore a variety of techniques, including bidirectional lateral connection, sign pyramid network with auxiliary supervision, and frame-level self-distillation. The resulting model is called TwoStream-SLR, which is competent for sign language recognition (SLR). TwoStream-SLR is extended to a sign language translation (SLT) model, TwoStream-SLT, by simply attaching an extra translation network. Experimentally, our TwoStream-SLR and TwoStream-SLT achieve state-of-the-art performance on SLR and SLT tasks across a series of datasets including Phoenix-2014, Phoenix-2014T, and CSL-Daily.
@inproceedings{wang2024diffusion,
author = Zuo, Ronglai and Wei, Fangyun and Chen, Zenggui and Mak, Brian and Yang, Jiaolong and Tong, Xin}, title = {A Simple Baseline for Spoken Language to Sign Language Translation with 3D Avatars}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2024} } |
|

|
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jiaolong Yang, Seungryong Kim, Chong Luo Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs The 40th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2024) (Highlight) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
This work delves into the task of pose-free novel view synthesis from stereo pairs, a challenging and pioneering task in 3D vision. Our innovative framework, unlike any before, seamlessly integrates 2D correspondence matching, camera pose estimation, and NeRF rendering, fostering a synergistic enhancement of these tasks. We achieve this through designing an architecture that utilizes a shared representation, which serves as a foundation for enhanced 3D geometry understanding. Capitalizing on the inherent interplay between the tasks, our unified framework is trained end-to-end with the proposed training strategy to improve overall model accuracy. Through extensive evaluations across diverse indoor and outdoor scenes from two real-world datasets, we demonstrate that our approach achieves substantial improvement over previous methodologies, especially in scenarios characterized by extreme viewpoint changes and the absence of accurate camera poses.
@inproceedings{hong2023unifying,
author = {Hong, Sunghwan and Jung, Jaewoo and Shin, Heeseong and Yang, Jiaolong and Kim, Seungryong and Luo, Chong}, title = {Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024} } |
|

|
Yue Wu+*, Sicheng Xu*, Jianfeng Xiang, Fangyun Wei, Qifeng Chen, Jiaolong Yang$, Xin Tong AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections ACM SIGGRAPH Asia 2023 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA. *: Equal contributuons. $: Corresponding author) |
|
Previous animatable 3D-aware GANs for human generation have primarily focused on either the human head or full body. However, head-only videos are relatively uncommon in real life, and full body generation typically does not deal with facial expression control and still has challenges in generating high-quality results. Towards applicable video avatars, we present an animatable 3D-aware GAN that generates portrait images with controllable facial expression, head pose, and shoulder movements. It is a generative model trained on unstructured 2D image collections without using 3D or video data. For the new task, we base our method on the generative radiance manifold representation and equip it with learnable facial and head-shoulder deformations. A dual-camera rendering and adversarial learning scheme is proposed to improve the quality of the generated faces, which is critical for portrait images. A pose deformation processing network is developed to generate plausible deformations for challenging regions such as long hair. Experiments show that our method, trained on unstructured 2D images, can generate diverse and high-quality 3D portraits with desired control over different properties.
@inproceedings{wu2023aniportraitgan,
author = {Wu, Yue and Xu, Sicheng and Xiang, Jianfeng and Wei, Fangyun and Chen, Qifeng and Yang, Jiaolong and Tong, Xin}, title = {AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections}, booktitle = {SIGGRAPH Asia 2023 Conference Proceedings}, year = {2023} } |
|

|
Jianfeng Xiang+, Jiaolong Yang, BinBin Huang, Xin Tong 3D-aware Image Generation using 2D Diffusion Models The 19th International Conference on Computer Vision (ICCV 2023) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
In this paper, we introduce a novel 3D-aware image generation method that leverages 2D diffusion models. We formulate the 3D-aware image generation task as multiview 2D image set generation, and further to a sequential unconditional–conditional multiview image generation process. This allows us to utilize 2D diffusion models to boost the generative modeling power of the method. Additionally, we incorporate depth information from monocular depth estimators to construct the training data for the conditional diffusion model using only still images. We train our method on a large-scale dataset, i.e., ImageNet, which is not addressed by previous methods. It produces high-quality images that significantly outperform prior methods. Furthermore, our approach showcases its capability to generate instances with large view angles, even though the training images are diverse and unaligned, gathered from “in-the-wild” real-world environments.
@inproceedings{xiang2022gramhd,
author = {Xiang, Jianfeng and Yang, Jiaolong and Huang, Binbin and Tong, Xin}, title = {3D-aware Image Generation using 2D Diffusion Models}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, year = {2023} } |
|

|
Jianfeng Xiang+, Jiaolong Yang, Yu Deng, Xin Tong GRAM-HD: 3D-Consistent Image Generation at High Resolution with Generative Radiance Manifolds The 19th International Conference on Computer Vision (ICCV 2023) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
Recent works have shown that 3D-aware GANs trained on unstructured single image collections can generate multiview images of novel instances. The key underpinnings to achieve this are a 3D radiance field generator and a volume rendering process. However, existing methods either cannot generate high-resolution images (e.g., up to 256x256) due to the high computation cost of neural volume rendering, or rely on 2D CNNs for image-space upsampling which jeopardizes the 3D consistency across different views. This paper proposes a novel 3D-aware GAN that can generate high resolution images (up to 1024x1024) while keeping strict 3D consistency as in volume rendering. Our motivation is to achieve super-resolution directly in the 3D space to preserve 3D consistency. We avoid the otherwise prohibitively-expensive computation cost by applying 2D convolutions on a set of 2D radiance manifolds defined in the recent generative radiance manifold (GRAM) approach, and apply dedicated loss functions for effective GAN training at high resolution. Experiments on FFHQ and AFHQv2 datasets show that our method can produce high-quality 3D-consistent results that significantly outperform existing methods. Videos can be found on the project page.
@inproceedings{xiang2022gramhd,
author = {Xiang, Jianfeng and Yang, Jiaolong and Deng, Yu and Tong, Xin}, title = {GRAM-HD: 3D-Consistent Image Generation at High Resolution with Generative Radiance Manifolds}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, year = {2023} } |
|

|
Yu Yin, Kamran Ghasedi, HsiangTao Wu, Jiaolong Yang, Xin Tong, Yun Fu NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-Shot Real Image Animation The 39th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2023) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
NeRF-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
@inproceedings{yin2023nerfinvertor,
author = {Yin, Yu and Ghasedi, Kamran and Wu, HsiangTao and Yang, Jiaolong and Tong, Xin and Fu, Yun}, title = {NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {8539-8548}, year = {2023} } |
|

|
Yue Wu+, Yu Deng+, Jiaolong Yang$, Fangyun Wei, Qifeng Chen, Xin Tong AniFaceGAN: Animatable 3D-Aware Face Image Generation for Video Avatars The 36th Conference on Neural Information Processing Systems (NeurIPS 2022) (Spotlight) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA. $: Corresponding author) |
|
Recent works have shown that 3D-aware GANs trained on unstructured single image collections can generate multiview images of novel instances. The key underpinnings to achieve this are a 3D radiance field generator and a volume rendering process. However, existing methods either cannot generate high-resolution images (e.g., up to 256X256) due to the high computation cost of neural volume rendering, or rely on 2D CNNs for image-space upsampling which jeopardizes the 3D consistency across different views. This paper proposes a novel 3D-aware GAN that can generate high resolution images (up to 1024X1024) while keeping strict 3D consistency as in volume rendering. Our motivation is to achieve super-resolution directly in the 3D space to preserve 3D consistency. We avoid the otherwise prohibitively-expensive computation cost by applying 2D convolutions on a set of 2D radiance manifolds defined in the recent generative radiance manifold (GRAM) approach, and apply dedicated loss functions for effective GAN training at high resolution. Experiments on FFHQ and AFHQv2 datasets show that our method can produce high-quality 3D-consistent results that significantly outperform existing methods. Videos can be found on the project page.
@inproceedings{xiang2022gramhd,
author = {Wu, Yue and Deng, Yu and Yang, Jiaolong and Wei, Fangyun and Chen, Qifeng and Tong, Xin}, title = {AniFaceGAN: Animatable 3D-Aware Face Image Generation for Video Avatars}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2022} } |
|

|
Ziyu Wang+, Yu Deng+, Jiaolong Yang, Jingyi Yu, Xin Tong Generative Deformable Radiance Fields for Disentangled Image Synthesis of Topology-Varying Objects The 30th Pacific Graphics Conference (PG 2022) (& Computer Graphics Forum, CGF) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
3D-aware generative models have demonstrated their superb performance to generate 3D neural radiance fields (NeRF) from a collection of monocular 2D images even for topology-varying object categories. However, these methods still lack the capability to separately control the shape and appearance of the objects in the generated radiance fields. In this paper, we propose a generative
model for synthesizing radiance fields of topology-varying objects with disentangled shape and appearance variations. Our method generates deformable radiance fields, which builds the dense correspondence between the density fields of the objects and encodes their appearances in a shared template field. Our disentanglement is achieved in an unsupervised manner without introducing extra labels to previous 3D-aware GAN training. We also develop an image inversion scheme for reconstructing the radiance field of an object in a real monocular image and manipulating its shape and appearance. Experiments show that our method can successfully learn the generative model from unstructured monocular images and well disentangle the shape and appearance for objects (e.g., chairs) with large topological variance. The model trained on synthetic data can faithfully reconstruct the real object in a given single image and achieve high-quality texture and shape editing results.
@inproceedings{wang2022generative,
author = {Wang, Ziyu and Deng, Yu and Yang, Jiaolong and Yu, Jingyi and Tong, Xin}, title = {Generative Deformable Radiance Fields for Disentangled Image Synthesis of Topology-Varying Objects}, booktitle = {Pacific Graphics}, year = {2022} } |
|
|
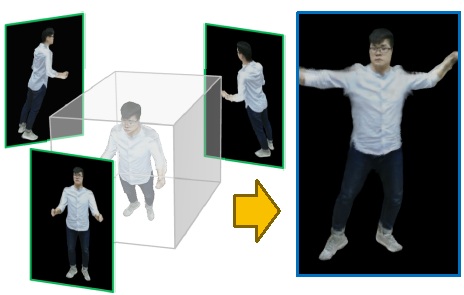
Xiangjun Gao+, Jiaolong Yang$, Jongyoo Kim, Sida Peng, Zicheng Liu, Xin Tong MPS-NeRF: Generalizable 3D Human Rendering from Multiview Images IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA. $: Corresponding author) |
|
There has been rapid progress recently on 3D human rendering, including novel view synthesis and pose animation, based on the advances of neural radiance fields (NeRF). However, most existing methods focus on person-specific training and their training typically requires multi-view videos. This paper deals with a new challenging task – rendering novel views and novel poses for a person unseen in training, using only multiview still images as input without videos. For this task, we propose a simple yet surprisingly effective method to train a generalizable NeRF with multiview images as conditional input. The key ingredient is a dedicated representation combining a canonical NeRF and a volume deformation scheme. Using a canonical space enables our method to learn shared properties of human and easily generalize to different people. Volume deformation is used to connect the canonical space with input and target images and query image features for radiance and density prediction. We leverage the parametric 3D human model fitted on the input images to derive the deformation, which works quite well in practice when combined with our canonical NeRF. The experiments on both real and synthetic data with the novel view synthesis and pose animation tasks ollectively demonstrate the efficacy of our method.
@inproceedings{deng2021gram,
author = {Gao, Xiangjun and Yang, Jiaolong and Kim, Jongyoo and Peng, Sida and Liu, Zicheng and Tong, Xin}, title = {MPS-NeRF: Generalizable 3D Human Rendering from Multiview Images}, booktitle = {IEEE Transactions on Pattern Analysis and Machine Intelligence (to appear)}, year = {2022} } |
|
|
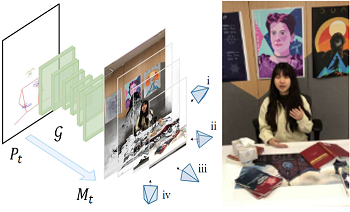
Hao Ouyang, Bo Zhang, Pan Zhang, Hao Yang, Jiaolong Yang, Dong Chen, Qifeng Chen, Fang Wen Real-Time Neural Character Rendering with Pose-Guided Multiplane Images The 17th European Conference on Computer Vision (ECCV2022) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
We propose pose-guided multiplane image (MPI) synthesis which can render an animatable character in real scenes with photorealistic quality. We use a portable camera rig to capture the multi-view images along with the driving signal for the moving subject. Our method generalizes the image-to-image translation paradigm, which translates the human pose to a 3D scene representation --- MPIs that can be rendered in free viewpoints, using the multi-views captures as supervision. To fully cultivate the potential of MPI, we propose depth-adaptive MPI which can be learned using variable exposure images while being robust to inaccurate camera registration. Our method demonstrates advantageous novel-view synthesis quality over the state-of-the-art approaches for characters with challenging motions. Moreover, the proposed method is generalizable to novel combinations of training poses and can be explicitly controlled. Our method achieves such expressive and animatable character rendering all in real time, serving as a promising solution for practical applications.
@inproceedings{hao2022real,
author = {Ouyang, Hao and Zhang, Bo and Zhang, Pan and Yang, Hao and Yang, Jiaolong and Chen, Dong and Chen, Qifeng and Wen, Fang}, title = {Real-Time Neural Character Rendering with Pose-Guided Multiplane Images}, booktitle = {European Conference on Computer Vision}, year = {2022} } |
|
|
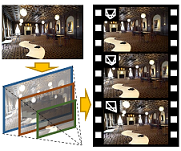
Yuxuan Han+, Ruicheng Wang+, Jiaolong Yang$ Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images ACM SIGGRAPH 2022 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA. $: Corresponding author) |
|
This paper deals with the challenging task of synthesizing novel views for in-the-wild photographs. Existing methods have shown promising results leveraging monocular depth estimation and color inpainting with layered depth representations. However, these methods still have limited capability to handle scenes with complex 3D geometry. We propose a new method based on the multiplane image (MPI) representation. To accommodate diverse scene layouts in the wild and tackle the difficulty in producing high-dimensional MPI contents, we design a network structure that consists of two novel modules, one for plane depth adjustment and another for depth-aware radiance prediction. The former adjusts the initial plane positions using the RGBD context feature and an attention mechanism. Given adjusted depth values, the latter predicts the color and density for each plane separately with proper inter-plane interactions achieved via a feature masking strategy. To train our method, we construct large-scale stereo training data using only unconstrained single-view image collections by a simple yet effective warp-back strategy. The experiments on both synthetic and real datasets demonstrate that our trained model works remarkably well and achieves state-of-the-art results.
@inproceedings{han2022single,
author = {Han, Yuxuan and Wang, Ruicheng and Yang, Jiaolong}, title = {Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images}, booktitle = {ACM SIGGRAPH}, year = {2022} } |
|
|
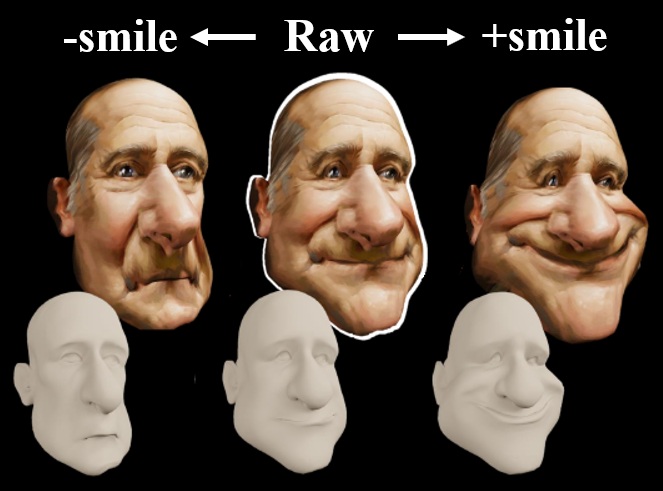
Yucheol Jung, Wonjong Jang, Soongjin Kim, Jiaolong Yang, Xin Tong, Seungyong Lee Deep Deformable 3D Caricatures with Learned Shape Control ACM SIGGRAPH 2022 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
A 3D caricature is an exaggerated 3D depiction of a human face. The goal of this paper is to model the variations of 3D caricatures in a compact parameter space so that we can provide a useful data-driven toolkit for handling 3D caricature deformations. To achieve the goal, we propose an MLP-based framework for building a deformable surface model, which takes a latent code and produces a 3D surface. In the framework, a SIREN MLP models a function that takes a 3D position on a fixed template surface and returns a 3D displacement vector for the input position. We create variations of 3D surfaces by learning a hypernetwork that takes a latent code and produces the parameters of the MLP. Once learned, our deformable model provides a nice editing space for 3D caricatures, supporting label-based semantic editing and point-handle-based deformation, both of which produce highly exaggerated and natural 3D caricature shapes. We also demonstrate other applications of our deformable model, such as automatic 3D caricature creation.
@inproceedings{deng2021gram,
author = {Jung, Yucheol and Jang, Wonjong and Kim, Soongjin and Yang, Jiaolong and Tong, Xin and Lee, Seungyong}, title = {Deep Deformable 3D Caricatures with Learned Shape Control}, booktitle = {ACM SIGGRAPH}, year = {2022} } |
|

|
Yizhong Zhang*, Jiaolong Yang*, Zhen Liu, Ruicheng Wang, Guojun Chen, Xin Tong, Baining Guo VirtualCube: An Immersive 3D Video Communication System IEEE Conference on Virtual Reality and 3D User Interfaces (VR2022) (& IEEE TVCG) (Best Paper Award. Check our project webpage!) [Abstract] [BibTex] [PDF] [Webpage] [arXiv] (*: Equal contributions) |
|
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.
@article{zhang2021virtualcube,
author = {Zhang, Yizhong and Yang, Jiaolong and Liu, Zhen and Wang, Ruicheng and Chen, Guojun and Tong, Xin and Guo, Baining}, title = {VirtualCube: An Immersive 3D Video Communication System}, booktitle = {IEEE Transactions on Visualization and Computer Graphics}, year = {2022} } |
|

|
Yu Deng+, Jiaolong Yang, Jianfeng Xiang, Xin Tong GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation The 38th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2022) (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
3D-aware image generative modeling aims to generate 3D-consistent images with explicitly controllable camera poses. Recent works have shown promising results by training neural radiance field (NeRF) generators on unstructured 2D images, but still can not generate highly-realistic images with fine details. A critical reason is that the high memory and computation cost of volumetric representation learning greatly restricts the number of point samples for radiance integration during training. Deficient sampling not only limits the expressive power of the generator to handle fine details but also impedes effective GAN training due to the noise caused by unstable Monte Carlo sampling. We propose a novel approach that regulates point sampling and radiance field learning on 2D manifolds, embodied as a set of learned implicit surfaces in the 3D volume. For each viewing ray, we calculate ray-surface intersections and accumulate their radiance generated by the network. By training and rendering such radiance manifolds, our generator can produce high quality images with realistic fine details and strong visual 3D consistency.
@inproceedings{deng2021gram,
author = {Deng, Yu and Yang, Jiaolong and Xiang, Jianfeng and Tong, Xin}, title = {GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } |
|

|
Xiaobin Hu, Wenqi Ren, Jiaolong Yang, Xiaochun Cao, David Wipf, Bjoern Menze, Xin Tong, Hongbin Zha Face Restoration via Plug-and-Play 3D Facial Priors IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021 [Abstract] [BibTex] [PDF] [Suppl. Material] [arXiv] |
|
State-of-the-art face restoration methods employ deep convolutional neural networks (CNNs) to learn a mapping between degraded and sharp facial patterns by exploring local appearance knowledge. However, most of these methods do not well exploit facial structures and identity information, and only deal with task-specific face restoration (e.g., face super-resolution or deblurring). In this paper, we propose cross-tasks and cross-models plug-and-play 3D facial priors to explicitly embed the network with the sharp facial structures for general face restoration tasks. Our 3D priors are the first to explore 3D morphable knowledge based on the fusion of parametric descriptions of face attributes (e.g., identity, facial expression, texture, illumination, and face pose). Furthermore, the priors can easily be incorporated into any network and are very efficient in improving the performance and accelerating the convergence speed. Firstly, a 3D face rendering branch is set up to obtain 3D priors of salient facial structures and identity knowledge. Secondly, for better exploiting this hierarchical information (i.e., intensity similarity, 3D facial structure, and identity content), a spatial attention module is designed for the image restoration problems. Extensive face restoration experiments including face super-resolution and deblurring demonstrate that the proposed 3D priors achieve superior face restoration results over the state-of-the-art algorithms
@article{hu2021face,
author = {Hu, Xiaobin and Ren, Wenqi and Yang, Jiaolong and Cao, Xiaochun and Wipf, David and Menze, Bjoern and Xin, Tong and Zha, Hongbin}, title = {Face Restoration via Plug-and-Play 3D Facial Priors}, booktitle = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2021} } |
|

|
Kaixuan Wei, Ying Fu, Yinqiang Zheng, Jiaolong Yang Physics-based Noise Modeling for Extreme Low-light Photography IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021 [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
Enhancing the visibility in extreme low-light environments is a challenging task. Under nearly lightless condition, existing image denoising methods could easily break down due to significantly low SNR. In this paper, we systematically study the noise statistics in the imaging pipeline of CMOS photosensors, and formulate a comprehensive noise model that can accurately characterize the real noise structures. Our novel model considers the noise sources caused by digital camera electronics which are largely overlooked by existing methods yet have significant influence on raw measurement in the dark. It provides a way to decouple the intricate noise structure into different statistical distributions with physical interpretations. Moreover, our noise model can be used to synthesize realistic training data for learning-based low-light denoising algorithms. In this regard, although promising results have been shown recently with deep convolutional neural networks, the success heavily depends on abundant noisy-clean image pairs for training, which are tremendously difficult to obtain in practice. Generalizing their trained models to images from new devices is also
problematic. Extensive experiments on multiple low-light denoising datasets – including a newly collected one in this work covering various devices – show that a deep neural network trained with our proposed noise formation model can reach surprisingly-high accuracy. The results are on par with or sometimes even outperform training with paired real data, opening a new door to real-world extreme low-light photography.
@article{wei2021physics,
author = {Wei, Kaixuan and Fu, Ying and Zheng, Yinqiang and Yang, Jiaolong}, title = {Physics-based Noise Modeling for Extreme Low-light Photography}, booktitle = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2021} } |
|

|
Jongyoo Kim, Jiaolong Yang, Xin Tong Learning High-Fidelity Face Texture Completion without Complete Face Texture The 18th International Conference on Computer Vision (ICCV2021) [Abstract] [BibTex] [PDF] [Suppl. Material] [arXiv] |
|
For face texture completion, previous methods typically use some complete textures captured by multiview imaging systems or 3D scanners for supervised learning. This paper deals with a new challenging problem – learning to complete invisible texture in a single face image without using any complete texture. We simply leverage a large corpus of face images of different subjects (e. g., FFHQ) to train a texture completion model in an unsupervised manner. To achieve this, we propose DSD-GAN, a novel deep neural network based method that applies two discriminators in UV map space and image space. These two discriminators work in a complementary manner to learn both facial structures and texture details. We show that their combination is essential to obtain high-fidelity results. Despite the network never sees any complete facial appearance, it is able to generate compelling full textures from single images.
@inproceedings{kim2021learning,
author = {Kim, Jongyoo and Yang, Jiaolong and Tong, Xin}, title = {Learning High-Fidelity Face Texture Completion without Complete Face Texture}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, year = {2021} } |
|
|
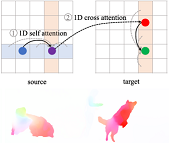
Haofei Xu+, Jiaolong Yang, Jianfei Cai, Juyong Zhang, Xin Tong High-Resolution Optical Flow from 1D Attention and Correlation The 18th International Conference on Computer Vision (ICCV2021) (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
Optical flow is inherently a 2D search problem, and thusthe computational complexity grows quadratically with respect to the search window, making large displacements matching infeasible for high-resolution images. In this pa-per, we propose a new method for high-resolution opticalflow estimation with significantly less computation, whichis achieved by factorizing 2D optical flow with 1D attentionand correlation. Specifically, we first perform a 1D atten-tion operation in the vertical direction of the target image,and then a simple 1D correlation in the horizontal direc-tion of the attended image can achieve 2D correspondencemodeling effect. The directions of attention and correlationcan also be exchanged, resulting in two 3D cost volumesthat are concatenated for optical flow estimation. The novel1D formulation empowers our method to scale to very high-resolution input images while maintaining competitive per-formance. Extensive experiments on Sintel, KITTI and real-world 4K (2160×3840) resolution images demonstrated theeffectiveness and superiority of our proposed method.
@inproceedings{xu2021high,
author = {Xu, Haofei and Yang, Jiaolong and Cai, Jianfei and Zhang, Juyong and Tong, Xin}, title = {High-Resolution Optical Flow from 1D Attention and Correlation}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, year = {2021} } |
|
|
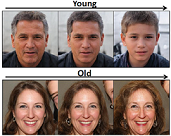
Yuxuan Han, Jiaolong Yang, Ying Fu Disentangled Face Attribute Editing via Instance-Aware Latent Space Search The 30th International Joint Conference on Artificial Intelligence (IJCAI2021) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
Recent works have shown that a rich set of semantic directions exist in the latent space of Generative Adversarial Networks (GANs), which enables various facial attribute editing applications. However, existing methods may suffer poor attribute variation disentanglement, leading to unwanted change of other attributes when altering the desired one. The semantic directions used by existing methods are at attribute level, which are difficult to model complex attribute correlations, especially in the presence of attribute distribution bias in GAN’s training set. In this paper, we propose a novel framework (IALS) that performs Instance-Aware Latent-Space Search to find semantic directions for disentangled attribute editing. The instance information is injected by leveraging the supervision from a set of attribute classifiers evaluated on the input images. We further propose a Disentanglement-Transformation (DT) metric to quantify the attribute transformation and disentanglement efficacy and find the optimal control factor between attribute-level and instance-specific directions based on it. Experimental results on both GAN-generated and real-world images collectively show that our method outperforms state-of-the-art methods proposed recently by a wide margin.
@inproceedings{han2021disentangled,
author = {Han, Yuxuan and Yang, Jiaolong and Fu, Ying}, title = {Disentangled Face Attribute Editing via Instance-Aware Latent Space Search}, booktitle = {Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI)}, year = {2021} } |
|

|
Wongjong Jang, Gwangjin Ju, Yucheol Jung, Jiaolong Yang, Xin Tong, Seungyong Lee StyleCariGAN: Caricature Generation via StyleGAN Feature Map Modulation ACM Transactions on Graphics (TOG), 2021 (Proc. SIGGRAPH2021) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
We present a caricature generation framework based on shape and style manipulation using StyleGAN. Our framework, dubbed StyleCariGAN, automatically creates a realistic and detailed caricature from an input photo with optional controls on shape exaggeration degree and color stylization type. The key component of our method is shape exaggeration blocks that are used for modulating coarse layer feature maps of StyleGAN to produce desirable caricature shape exaggerations. We first build a layer-mixed StyleGAN for photo-to-caricature style conversion by swapping fine layers of the StyleGAN for photos to the corresponding layers of the StyleGAN trained to generate caricatures. Given an input photo, the layer-mixed model produces detailed color stylization for a caricature but without shape exaggerations. We then append shape exaggeration blocks to the coarse layers of the layer-mixed model and train the blocks to create shape exaggerations while preserving the characteristic appearances of the input. Experimental results show that our StyleCariGAN generates realistic and detailed caricatures compared to the current state-of-the-art methods. We demonstrate StyleCariGAN also supports other StyleGAN-based image manipulations, such as facial expression control.
@article{jang2021stylecarigan,
author = {Jang, Wongjong and Ju, Gwangjin and Jung, Yucheol and Yang, Jiaolong and Xin, Tong and Lee, Seungyong}, title = {StyleCariGAN: Caricature Generation via StyleGAN Feature Map Modulation}, journal = {ACM Transactions on Graphics}, year = {2021} } |
|

|
Yu Deng+, Jiaolong Yang, Xin Tong Deformed Implicit Field: Modeling 3D Shapes with Learned Dense Correspondence The 37th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2021) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
We propose a novel Deformed Implicit Field (DIF) representation for modeling 3D shapes of a category and generating dense correspondences among shapes. With DIF, a 3D shape is represented by a template implicit field shared across the category, together with a 3D deformation field and a correction field dedicated for each shape instance. Shape correspondences can be easily established using their deformation fields. Our neural network, dubbed DIF-Net, jointly learns a shape latent space and these fields for 3D objects belonging to a category without using any correspondence or part label. The learned DIF-Net can also provides reliable correspondence uncertainty measurement reflecting shape structure discrepancy. Experiments show that DIF-Net not only produces high-fidelity 3D shapes but also builds high-quality dense correspondences across different shapes. We also demonstrate several applications such as texture transfer and shape editing, where our method achieves compelling results that cannot be achieved by previous methods.
@inproceedings{deng2020deformed,
author = {Deng, Yu and Yang, Jiaolong and Xin, Tong}, title = {Deformed Implicit Field: Modeling 3D Shapes with Learned Dense Correspondence}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {10286-10296}, year = {2020} } |
|

|
Yu Deng+, Jiaolong Yang, Dong Chen, Fang Wen, Xin Tong Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning The 36th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2020), Seattle, USA (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
We propose DiscoFaceGAN, an approach for face image generation of virtual people with disentangled, precisely-controllable latent representations for identity, expression, pose, and illumination. We embed 3D priors into adversarial learning and train the network to imitate the image formation of an analytic 3D face deformation and rendering process. To deal with the generation freedom induced by the domain gap between real and rendered faces, we further introduce contrastive learning to promote disentanglement by comparing pairs of generated images. Experiments show that through our imitative-contrastive learning, the factor variations are very well disentangled and the properties of a generated face can be precisely controlled. We also analyze the learned latent space and present several meaningful properties supporting factor disentanglement. Our method can also be used to embed real images into the disentangled latent space. We hope our method could provide new understandings of the relationship between physical properties and deep image synthesis.
@inproceedings{deng2020disentangled,
author = {Deng, Yu and Yang, Jiaolong and Chen, Dong and Wen, Fang and Xin, Tong}, title = {Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {5154-5163}, year = {2020} } |
|

|
Sicheng Xu+, Jiaolong Yang, Dong Chen, Fang Wen, Yu Deng, Yunde Jia, Xin Tong Deep 3D Portrait from a Single Image The 36th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2020), Seattle, USA [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
In this paper, we present a learning-based approach for recovering the 3D geometry of human head from a single portrait image. Our method is learned in an unsupervised manner without any ground-truth 3D data. We represent the head geometry with a parametric 3D face model together with a depth map for other head regions including hair and ear. A two-step geometry learning scheme is proposed to learn 3D head reconstruction from in-the-wild face images, where we first learn face shape on single images using self-reconstruction and then learn hair and ear geometry using pairs of images in a stereo-matching fashion. The second step is based on the output of the first to not only improve the accuracy but also ensure the consistency of overall head geometry. We evaluate the accuracy of our method both in 3D and with pose manipulation tasks on 2D images. We alter pose based on the recovered geometry and apply a refinement network trained with adversarial learning to ameliorate the reprojected images and translate them to the real image domain. Extensive evaluations and comparison with previous methods show that our new method can produce high-fidelity 3D head geometry and head pose manipulation results.
@inproceedings{xu2020deep,
author = {Xu, Sicheng and Yang, Jiaolong and Chen, Dong and Wen, Fang and Deng, Yu and Jia, Yunde and Xin, Tong}, title = {Deep 3D Portrait from a Single Image}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {7710-7720}, year = {2020} } |
|

|
Kaixuan Wei, Ying Fu, Jiaolong Yang, Hua Huang A Physics-based Noise Formation Model for Extreme Low-light Raw Denoising The 36th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2020), Seattle, USA (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
Lacking rich and realistic data, learned single image denoising algorithms generalize poorly to real raw images that do not resemble the data used for training. Although the problem can be alleviated by the heteroscedastic Gaussian model for noise synthesis, the noise sources caused by digital camera electronics are still largely overlooked, despite their significant effect on raw measurement, especially under extremely low-light condition. To address this issue, we present a highly accurate noise formation model based on the characteristics of CMOS photosensors, thereby enabling us to synthesize realistic samples that better match the physics of image formation process. Given the proposed noise model, we additionally propose a method to calibrate the noise parameters for available modern digital cameras, which is simple and reproducible for any new device. We systematically study the generalizability of a neural network trained with existing schemes, by introducing a new low-light denoising dataset that covers many modern digital cameras from diverse brands. Extensive empirical results collectively show that by utilizing our proposed noise formation model, a network can reach the capability as if it had been trained with rich real data, which demonstrates the effectiveness of our noise formation model.
@inproceedings{wei2020physics,
author = {Wei, Kaixuan and Fu, Ying and Yang, Jiaolong and Huang, Hua}, title = {A Physics-based Noise Formation Model for Extreme Low-light Raw Denoising}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {2758-2767}, year = {2020} } |
|

|
Wenqi Ren*, Jiaolong Yang*, Senyou Deng, David Wipf, Xiaochun Cao, Xin Tong Face Video Deblurring using 3D Facial Priors The 17th International Conference on Computer Vision (ICCV2019), Seoul, Korea (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributions) |
|
Existing face deblurring methods only consider single frames and do not account for facial structure and identity information. These methods struggle to deblur face videos that exhibit significant pose variations and misalignment. In this paper we propose a novel face video deblurring network capitalizing on 3D facial priors. The model consists of two main branches: i) a face video deblurring sub-network based on the encoder-decoder architecture, and ii) a 3D face rendering branch for predicting 3D priors of salient facial structures and identity knowledge. These structures encourage the deblurring branch to generate sharp faces with detailed structures. Our method not only uses low-level information (i.e., intensity similarity), but also middle-level information (i.e., 3D facial structure) and high-level knowledge (i.e., identity content) to further explore spatial constraints of facial components from blurry face frames. Extensive experimental results demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods.
@inproceedings{ren2019face,
author = {Ren, Wenqi and Yang, Jiaolong and Deng, Senyou and Wipf, David and Cao, Xiaochun and Xin, Tong}, title = {Face Video Deblurring using a 3D Facial Prior}, booktitle = {Proceedings of the International Conference on Computer Vision (ICCV)}, pages = {9388-9397}, year = {2019} } |
|
|
Kaixuan Wei, Jiaolong Yang, Ying Fu, David Wipf, Hua Huang Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements The 35th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2019), Long Beach, USA [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] |
|
Removing undesirable reflections from a single image captured through a glass window is of practical importance to visual computing systems. Although state-of-the-art methods can obtain decent results in certain situations, performance declines significantly when tackling more general real-world cases. These failures stem from the intrinsic difficulty of single image reflection removal--the fundamental ill-posedness of the problem, and the insufficiency of densely-labeled training data needed for resolving this ambiguity within learning-based neural network pipelines. In this paper, we address these issues by exploiting targeted network enhancements and the novel use of misaligned data. For the former, we augment a baseline network architecture by embedding context encoding modules that are capable of leveraging high-level contextual clues to reduce indeterminacy within areas containing strong reflections. For the latter, we introduce an alignment-invariant loss function that facilitates exploiting misaligned real-world training data that is much easier to collect. Experimental results collectively show that our method outperforms the state-of-the-art with aligned data, and that significant improvements are possible when using additional misaligned data.
@inproceedings{wei2019single,
author = {Wei, Kaixuan and Yang, Jiaolong and Fu, Ying and Wipf, David and Huang, Hua}, title = {Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements}, booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {8178-8187}, year = {2019} } |
|

|
Yu Deng+, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set IEEE Computer Vision and Pattern Recognition Workshop on AMFG (CVPRW2019), Long Beach, USA (Best Paper Award. Check out our code!) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
Recently, deep learning based 3D face reconstruction methods have shown promising results in both quality and efficiency. However, training deep neural networks typically requires a large volume of data, whereas face images with ground-truth 3D face shapes are scarce. In this paper, we propose a novel deep 3D face reconstruction approach that 1) leverages a robust, hybrid loss function for weakly-supervised learning which takes into account both
low-level and perception-level information for supervision, and 2) performs multi-image face reconstruction by exploiting complementary information from different images for shape aggregation. Our method is fast, accurate, and robust to occlusion and large pose. We provide comprehensive experiments on MICC Florence and Facewarehouse datasets, systematically comparing our method with fifteen recent methods and demonstrating its state-of-the-art performance.
@inproceedings{deng2019accurate,
author = {Deng, Yu and Yang, Jiaolong and Xu, Sicheng and Chen, Dong and Jia, Yunde and Tong, Xin}, title = {Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set}, booktitle = {Proceedings of IEEE Computer Vision and Pattern Recognition Workshop on Analysis and Modeling of Faces and Gestures}, year = {2019} } |
|

|
Hanqing Wang+, Jiaolong Yang, Wei Liang and Xin Tong Deep Single-View 3D Object Reconstruction with Visual Hull Embedding The 33rd AAAI Conference on Artificial Intelligence (AAAI2019), Honolulu, USA (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
3D object reconstruction is a fundamental task of many robotics and AI problems. With the aid of deep convolutional neural networks (CNNs), 3D object reconstruction has witnessed a significant progress in recent years. However, possibly due to the prohibitively high dimension of the 3D object space, the results from deep CNNs are often prone to missing some shape details. In this paper, we present an approach which aims to preserve more shape details and improve the reconstruction quality. The key idea of our method is to leverage object mask and pose estimation from CNNs to assist the 3D shape learning by constructing a probabilistic single-view visual hull inside of the network. Our method works by first predicting a coarse shape as well as the object pose and silhouette using CNNs, followed by a novel 3D refinement CNN which refines the coarse shapes using the constructed probabilistic visual hulls. Experiment on both synthetic data and real images show that embedding a single-view visual hull for shape refinement can significantly improve the reconstruction quality by recovering more shapes details and improving shape consistency with the input image.
@inproceedings{wang2019deep,
author = {Wang, Hanqing and Yang, Jiaolong and Liang, Wei and Tong, Xin}, title = {Deep Single-View 3D Object Reconstruction with Visual Hull Embedding}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, year = {2019} } |
|
|
Qingnan Fan+, Jiaolong Yang, David Wipf, Baoquan Chen and Xin Tong Image Smoothing via Unsupervised Learning ACM Transactions on Graphics (TOG), 2018 (Proc. SIGGRAPH Asia 2018) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
Image smoothing represents a fundamental component of many disparate computer vision and graphics applications. In this paper, we present a unified unsupervised (label-free) learning framework that facilitates generating flexible and high-quality smoothing effects by directly learning from data using deep convolutional neural networks (CNNs). The heart of the design is the training signal as a novel energy function that includes an edge-preserving regularizer which helps maintain important yet potentially vulnerable image structures, and a spatially-adaptive Lp flattening criterion which imposes different forms of regularization onto different image regions for better smoothing quality. We implement a diverse set of image smoothing solutions employing the unified framework targeting various applications such as, image abstraction, pencil sketching, detail enhancement, texture removal and content-aware image manipulation, and obtain results comparable with or better than previous methods. Moreover, our method is extremely fast with a modern GPU (e.g, 200 fps for 1280×720 images).
@article{fan2018image,
author = {Fan, Qingnan and Yang, Jiaolong and Wipf, David and Chen, Baoquan and Tong, Xin}, title = {Image Smoothing via Unsupervised Learning}, booktitle = {ACM Transactions on Graphics}, volume = {37}, number = {6}, pages = {1--14}, year = {2018} } |
|
|
Dongqing Zhang*, Jiaolong Yang*, Dongqiangzi Ye* and Gang Hua LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks The 15th European Conference on Computer Vision (ECCV2018), Munich, Germany [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (*: Equal contributions) |
|
Although weight and activation quantization is an effective approach for Deep Neural Network (DNN) compression and has a lot of potentials to increase inference speed leveraging bit-operations, there is still a noticeable gap in terms of prediction accuracy between the quantized model and the full-precision model. To address this gap, we propose to jointly train a quantized, bit-operation-compatible DNN and its associated quantizers, as opposed to using fixed, handcrafted quantization schemes such as uniform or logarithmic quantization. Our method for learning the quantizers applies to both network weights and activations with arbitrary-bit precision, and our quantizers are easy to train. The comprehensive experiments on CIFAR-10 and ImageNet datasets show that our method works consistently well for various network structures such as AlexNet, VGG-Net, GoogLeNet, ResNet, and DenseNet, surpassing previous quantization methods in terms of accuracy by an appreciable margin. Code available at https://github.com/Microsoft/LQ-Nets
@inproceedings{zhang2018optimized,
author = {Zhang, Dongqiang and Yang, Jiaolong and Ye, Dongqiangzi and Hua, Gang}, title = {LQ-Nets: Learned Quantization for Highly Accurate and Compact Deep Neural Networks}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2018} } |
|

|
Qingnan Fan+, Jiaolong Yang, Gang Hua, Baoquan Chen and David Wipf Revisiting Deep Intrinsic Image Decompositions The 34th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2018), Salt Lake City, USA (Oral) [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
While invaluable for many computer vision applications, decomposing a natural image into intrinsic reflectance and shading layers represents a challenging, underdetermined inverse problem. As opposed to strict reliance on conventional optimization or filtering solutions with strong prior assumptions, deep learning-based approaches have also been proposed to compute intrinsic image decompositions when granted access to sufficient labeled training data. The downside is that current data sources are quite limited, and broadly speaking fall into one of two categories: either dense fully-labeled images in synthetic/narrow settings, or weakly-labeled data from relatively diverse natural scenes. In contrast to many previous learning-based approaches, which are often tailored to the structure of a particular dataset (and may not work well on others), we adopt core network structures that universally reflect loose prior knowledge regarding the intrinsic image formation process and can be largely shared across datasets. We then apply flexibly supervised loss layers that are customized for each source of ground truth labels. The resulting deep architecture achieves state-of-the-art results on all of the major intrinsic image benchmarks, and runs considerably faster than most at test time.
@inproceedings{fan2018revisiting,
author = {Fan, Qingnan and Yang, Jiaolong and Hua, Gang and Chen, Baoquan and Wipf, David}, title = {Revisiting Deep Intrinsic Image Decompositions}, booktitle = {Proceedings of the 34th IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {8944-8952}, year = {2018} } |
|
|
Qingnan Fan+, Jiaolong Yang, Gang Hua, Baoquan Chen and David Wipf A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing The 16th International Conference on Computer Vision (ICCV2017), Venice, Italy [Abstract] [BibTex] [PDF] [Webpage] [Suppl. Material] [arXiv] (+: Intern at MSRA) |
|
This paper proposes a deep neural network structure that exploits edge information in addressing representative low-level vision tasks such as layer separation and image filtering. Unlike most other deep learning strategies applied in this context, our approach tackles these challenging problems by estimating edges and reconstructing images using only cascaded convolutional layers arranged such that no handcrafted or application-specific image-processing components are required. We apply the resulting transferrable pipeline to two different problem domains that are both sensitive to edges, namely, single image reflection removal and image smoothing. For the former, using a mild reflection smoothness assumption and a novel synthetic data generation method that acts as a type of weak supervision, our network is able to solve much more difficult reflection cases that cannot be handled by previous methods. For the latter, we also exceed the state-of-the-art quantitative and qualitative results by wide margins. In all cases, the proposed framework is simple, fast, and easy to transfer across disparate domains.
@inproceedings{fan2017generic,
author = {Fan, Qingnan and Yang, Jiaolong and Hua, Gang and Chen, Baoquan and Wipf, David}, title = {A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing}, booktitle = {Proceedings of the 16th International Conference on Computer Vision (ICCV)}, pages = {3238-3247}, year = {2017} } |
|

|
Chen Zhou+, Jiaolong Yang, Chunshui Zhao and Gang Hua Fast, Accurate Thin-Structure Obstacle Detection for Autonomous Mobile Robots IEEE Computer Vision and Pattern Recognition Workshop on Embedded Vision (CVPRW2017), Honolulu, USA [Abstract] [BibTex] [PDF] [arXiv] (+: Intern at MSRA) |
|
Safety is paramount for mobile robotic platforms such as self-driving cars and unmanned aerial vehicles. This work is devoted to a task that is indispensable for safety yet was largely overlooked in the past -- detecting obstacles that are of very thin structures, such as wires, cables and tree branches. This is a challenging problem, as thin objects can be problematic for active sensors such as lidar and sonar and even for stereo cameras. In this work, we propose to use video sequences for thin obstacle detection. We represent obstacles with edges in the video frames, and reconstruct them in 3D using efficient edge-based visual odometry techniques. We provide both a monocular camera solution and a stereo camera solution. The former incorporates Inertial Measurement Unit (IMU) data to solve scale ambiguity, while the latter enjoys a novel, purely vision-based solution. Experiments demonstrated that the proposed methods are fast and able to detect thin obstacles robustly and accurately under various conditions.
@inproceedings{yang2017neural,
author = {Zhou, Chen and Yang, Jiaolong and Zhao, Chunshui and Hua, Gang}, title = {Fast, Accurate Thin-Structure Obstacle Detection for Autonomous Mobile Robots}, booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, pages = {1-10}, year = {2017} } |
|
|
Jiaolong Yang, Peiran Ren, Dongqing Zhang, Dong Chen, Fang Wen, Hongdong Li and Gang Hua Neural Aggregation Network for Video Face Recognition The 33th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017), Honolulu, USA [Abstract] [BibTex] [PDF] [arXiv] |
|
We present a Neural Aggregation Network (NAN) for video face recognition. The network takes a face video or face image set of a person with a variable number of face images as its input, and produces a compact and fixed-dimension feature representation. The whole network is composed of two modules. The feature embedding module is a deep Convolutional Neural Network (CNN), which maps each face image into a feature vector. The aggregation module consists of two attention blocks driven by a memory storing all the extracted features. It adaptively aggregates the features to form a single feature inside the convex hull spanned by them. Due to the attention mechanism, the aggregation is invariant to the image order. We found that NAN learns to advocate high-quality face images while repelling low-quality ones such as blurred, occluded and improperly exposed faces. The experiments on IJB-A, YouTube Face, Celebrity-1000 video face recognition benchmarks show that it consistently outperforms standard aggregation methods and achieves state-of-the-art accuracies.
@inproceedings{yang2017neural,
author = {Yang, Jiaolong and Ren, Peiran and Zhang, Dongqing and Chen, Dong and Wen, Fang and Li, Hongdong and Hua, Gang}, title = {Neural Aggregation Network for Video Face Recognition}, booktitle = {Proceedings of the 32th IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {4362-4371}, year = {2017} } |
|

|
Jiaolong Yang, Hongdong Li, Yuchao Dai and Robby T. Tan Robust Optical Flow Estimation of Double-Layer Images under Transparency or Reflection The 32th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), Las Vegas, USA [Abstract] [BibTex] [PDF] [Suppl. Material] |
|
This paper deals with a challenging, frequently encountered, yet not properly investigated problem in two-frame optical flow estimation. That is, the input frames are compounds of two imaging layers - one desired background layer of the scene, and one distracting, possibly moving layer due to transparency or reflection. In this situation, the conventional brightness constancy constraint - the cornerstone of most existing optical flow methods - will no longer be valid. In this paper, we propose a robust solution to this problem. The proposed method performs both optical flow estimation, and image layer separation. It exploits a generalized double-layer brightness consistency constraint connecting these two tasks, and utilizes the priors for both of them. Experiments on both synthetic data and real images have confirmed the efficacy of the proposed method. To the best of our knowledge, this is the first attempt towards handling generic optical flow fields of two-frame images containing transparency or reflection.
@inproceedings{yang2016robust,
author = {Yang, Jiaolong and Li, Hongdong and Dai, Yuchao and Tan, Robby T.}, title = {Robust Optical Flow Estimation of Double-Layer Images under Transparency or Reflection}, booktitle = {Proceedings of the 32th IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {1410-1419}, year = {2016} } |
|

|
Jiaolong Yang, Hongdong Li, Dylan Campbell and Yunde Jia Go-ICP: A Globally Optimal Solution to 3D ICP Point-Set Registration IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2016 [Abstract] [BibTex] [PDF] [Suppl. Material] |
|
The Iterative Closest Point (ICP) algorithm is one of the most widely used methods for point-set registration. However, being based on local iterative optimization, ICP is known to be susceptible to local minima. Its performance critically relies on the quality of the initialization and only local optimality is guaranteed. This paper presents the first globally optimal algorithm, named Go-ICP, for Euclidean (rigid) registration of two 3D point-sets under the L2 error metric defined in ICP. The Go-ICP method is based on a branch-and-bound (BnB) scheme that searches the entire 3D motion space SE(3). By exploiting the special structure of SE(3) geometry, we derive novel upper and lower bounds for the registration error function. Local ICP is integrated into the BnB scheme, which speeds up the new method while guaranteeing global optimality. We also discuss extensions, addressing the issue of outlier robustness. The evaluation demonstrates that the proposed method is able to produce reliable registration results regardless of the initialization. Go-ICP can be applied in scenarios where an optimal solution is desirable or where a good initialization is not always available.
@article{yang2016goicp,
author = {Yang, Jiaolong and Li, Hongdong and Campbell, Dylan and Jia, Yunde}, title = {Go-ICP: A Globally Optimal Solution to 3D ICP Point-Set Registration}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI)}, volume = {38}, number = {11}, pages = {2241--2254}, year = {2016} } |
|

|
Jiaolong Yang and Hongdong Li Dense, Accurate Optical Flow Estimation with Piecewise Parametric Model The 31th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2015), Boston, USA [Abstract] [BibTex] [PDF] [Extended Abstract] [Suppl. Material] |
|
This paper proposes a simple method for estimating dense and accurate optical flow field. It revitalizes an early idea of piecewise parametric flow model. A key innovation is that we fit a flow field piecewise to a variety of parametric models, where the domain of each piece (i.e., each piece's shape, position and size) as well as the total number of pieces are determined adaptively, while at the same time maintaining a global inter-piece flow continuity constraint. We achieve this by a multi-model fitting scheme via energy minimization. Our energy takes into account both the piecewise constant model assumption, and the flow field continuity constraint. The proposed method effectively handles both homogeneous regions and complex motion. Experiments on three public optical flow benchmarks (KITTI, MPI Sintel, and Middlebury) show the superiority of our method compared with the state of the art: it achieves top-tier performances on all the three benchmarks.
@inproceedings{yang2015dense,
author = {Yang, Jiaolong and Li, Hongdong}, title = {Dense, Accurate Optical Flow Estimation with Piecewise Parametric Model}, booktitle = {Proceedings of the 31th IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {1019-1027}, year = {2015} } |
|

|
Jiaolong Yang, Hongdong Li and Yunde Jia Optimal Essential Matrix Estimation via Inlier-Set Maximization The 13th European Conference on Computer Vision (ECCV2014), Zürich, Switzerland [Abstract] [BibTex] [PDF] |
|
In this paper, we extend the globally optimal "rotation space search" method [11] to essential matrix estimation in the presence of feature mismatches or outliers. The problem is formulated as inlier-set cardinality maximization, and solved via branch-and-bound global optimization which searches the entire essential manifold formed by all essential matrices. Our main contributions include an explicit, geometrically meaningful essential manifold parametrization using a 5D direct product space of a solid 2D disk and a solid 3D ball, as well as efficient closed-form bounding functions. Experiments on both synthetic data and real images have confirmed the efficacy of our method. The method is mostly suitable for applications where robustness and accuracy are paramount. It can also be used as a benchmark for method evaluation.
@inproceedings{yang2014optimal,
author = {Yang, Jiaolong and Li, Hongdong and Jia, Yunde}, title = {Optimal Essential Matrix Estimation via Inlier-Set Maximization}, booktitle = {Proceedings of the 14th European Conference on Computer Vision (ECCV)}, pages = {111-126}, year = {2014} } |
|
|
Jiaolong Yang, Hongdong Li and Yunde Jia Go-ICP: Solving 3D Registration Efficiently and Globally Optimally The 14th International Conference on Computer Vision (ICCV2013), Sydney, Australia [Abstract] [BibTex] [PDF] |
|
Registration is a fundamental task in computer vision. The Iterative Closest Point (ICP) algorithm is one of the widely-used methods for solving the registration problem. Based on local iteration, ICP is however well-known to suffer from local minima. Its performance critically relies on the quality of initialization, and only local optimality is guaranteed. This paper provides the very first globally optimal solution to Euclidean registration of two 3D pointsets or two 3D surfaces under the L2 error. Our method is built upon ICP, but combines it with a branch-and-bound (BnB) scheme which searches the 3D motion space SE(3) efficiently. By exploiting the special structure of the underlying geometry, we derive novel upper and lower bounds for the ICP error function. The integration of local ICP and global BnB enables the new method to run efficiently in practice, and its optimality is exactly guaranteed. We also discuss extensions, addressing the issue of outlier robustness.
@inproceedings{yang2013goicp,
author = {Yang, Jiaolong and Li, Hongdong and Jia, Yunde}, title = {Go-ICP: Solving 3D Registration Efficiently and Globally Optimally}, booktitle = {Proceedings of the 14th International Conference on Computer Vision (ICCV)}, pages = {1457-1464}, year = {2013} } |
|

|
Jiaolong Yang, Yuchao Dai, Hongdong Li, Henry Gardner and Yunde Jia Single-shot Extrinsic Calibration of a Generically Configured RGB-D Camera Rig from Scene Constraints The 12th International Symposium on Mixed and Augmented Reality (ISMAR2013), Adelaide, Australia (Oral) [Abstract] [BibTex] [PDF] |
|
With the increasingly popular use of commodity RGB-D cameras for computer vision, robotics, mixed and augmented reality and other areas, it is of significant practical interest to calibrate the relative pose between a depth (D) camera and an RGB camera in these types of setups. In this paper, we propose a new single-shot, correspondence-free method to extrinsically calibrate a generically configured RGB-D camera rig. We formulate the extrinsic calibration problem as one of geometric 2D-3D registration which exploits scene constraints to achieve single-shot extrinsic calibration. Our method first reconstructs sparse point clouds from single view 2D image, which are then registered with dense point clouds from the depth camera. Finally, we directly optimize the warping quality by evaluating scene constraints in 3D point clouds. Our single-shot extrinsic calibration method does not require correspondences across multiple color images or across modality, achieving greater flexibility over existing methods. The scene constraints required by our method can be very simple and we demonstrate that a scene made up of three sheets of paper is sufficient to obtain reliable calibration and with lower geometric error than existing methods.
@inproceedings{yang2013single,
author = {Yang, Jiaolong and Dai, Yuchao and Li, Hongdong and Gardner, Henry and Jia, Yunde}, title = {Single-shot Extrinsic Calibration of a Generically Configured RGB-D Camera Rig from Scene Constraints}, booktitle = {Proceedings of the 12th International Symposium on Mixed and Augmented Reality (ISMAR)}, pages = {181-188}, year = {2013} } |
|
|
Jiaolong Yang, Wei Liang and Yunde Jia Face Pose Estimation with Combined 2D and 3D HOG Features The 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan [Abstract] [BibTex] [PDF] |
|
In this paper, a new stereo camera calibration technique that can realize automatic strong calibration is proposed. In order to achieve online camera calibration, an object covered with chess-board patterns, called embedded calibration device, is placed inside the cavity of the stereovision system. We estimate the structural configuration of the embedded calibration device, i.e. the 3D positions of all the grid points on the device, to calibrate the cameras. Since the device is close to the stereo camera, the calibration results are usually not valid for the volume around the object in the scene. Therefore we present a correction approach combining the embedded calibration and scene features to make the calibration valid in the scene. Experimental results demonstrate that our system performs robust and accurate, and is very applicable in unmanned systems.
@inproceedings{yang2012face,
author = {Yang, Jiaolong and Liang, Wei and Jia, Yunde}, title = {Face Pose Estimation with Combined 2D and 3D HOG Features}, booktitle = {Proceedings of the 21st International Conference on Pattern Recognition (ICPR)}, pages = {2492-2495}, year = {2012} } |
|
Earlier: Xiameng Qin, Jiaolong Yang, Wei Liang, Mingtao Pei and Yunde Jia. Stereo Camera Calibration with an Embedded Calibration Device and Scene Features. IEEE International Conference on Robotics and Biomimetics (ROBIO), pp. 2306-2310, 2012. Jiaolong Yang, Lei Chen and Yunde Jia. Human-robot Interaction Technique Based on Stereo Vision. Chinese Conference on Human Computer Interaction (CHCI), pp. 226-231, 2011. (in Chinese) Jiaolong Yang, Lei Chen and Wei Liang. Monocular Vision based Robot Self-localization. IEEE International Conference on Robotics and Biomimetics (ROBIO), pp. 1189-1193, 2010. Lei Chen, Mingtao Pei and Jiaolong Yang. Multi-Scale Matching for Data Association in Vision-based SLAM. IEEE International Conference on Robotics and Biomimetics (ROBIO), pp. 1183-1188, 2010. |
| Academic Services |
|
Conference Area Chair: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, 2022 International Conference on Computer Vision (ICCV), 2021, 2025 Winter Conference on Applications of Computer Vision (WACV), 2022 European Conference on Computer Vision (ECCV), 2024, 2026 ACM Multimedia Conference (MM), 2024
Conference Reviewer/Program Committee Member:
Journal Associate Editor/Editorial Board Member:
Journal Reviewer: |